یک دوربری کوانتومی دیگر به دست آمد-این بار بین دو تراشه رایانه

یک دوربری کوانتومی دیگر به دست آمد-این بار بین دو تراشه رایانه
پدیده ای که اینشتین آن را "اقدام ترسناک از راه دور" نامید ، ممکن است راه ارتباط ما را در آینده متحول سازد
ما در چند سال گذشته گام های بلندی در زمینه محاسبات کوانتومی برداشته ایم - در حال توسعه Google & IBM…
تجربه
 عکس توسط Clem Onojeghuo در Unsplash
عکس توسط Clem Onojeghuo در Unsplash تجربه
6 ماه به عنوان یادگیری ماشین/مهندس بینایی رایانه
گذراندن نیم سال در زمینه ای که چند سال پیش خود را در آن ندیده بودم
مقدمه
من نمی توانم باور کنم که شش ماه از نوشتن مقاله ای در مورد اولین روزم در نقش فعلی ام می گذرد.
زمان واقعا پرواز می کند.
بنابراین ، مجدداً به گزارش آنلاین تجربیات من به عنوان مهندس بینایی رایانه خوش آمدید.
در این مقاله ، می توانید جزئیات زیادی را در مورد فعالیتهای روزانه مهندس بینایی رایانه ای که در یک استارتاپ کار می کند ، انتظار داشته باشید. همچنین انتظار داشته باشید که برخی از اشتباهاتی که انجام داده ام و دستاوردهایی که به آنها اشاره کرده ام را به خاطر بیاورید.
برای شما ، این مقاله به شما نشان می دهد که در هنگام راه اندازی یادگیری ماشین/بینایی رایانه ای در یک راه اندازی ، چه انتظاری دارید. و نقشها و مسئولیتهای معمولی تمرین کننده ماشین یادگیری در زمان کنونی.
من فکر می کنم این یک معرفی کافی خوب است.
بیایید مستقیم وارد شویم و شش ماه را در 4000 کلمه خلاصه کنیم. ، یا کمتر.
یادگیری ماشین/بینایی کامپیوتر/یادگیری عمیق
 ترکیبی توسط ولادیسلاو اوسیاسیا. (مجوز تصویر متعلق به نویسنده است)
ترکیبی توسط ولادیسلاو اوسیاسیا. (مجوز تصویر متعلق به نویسنده است) بیایید با تفکیک نقش من ، همراه با شرح نقش شغل ، همه چیز را شروع کنیم.
در این بخش ، من همچنین دقیقاً آنچه از یک مهندس بینایی کامپیوتر انتظار می رود را به شما ارائه می دهد.
مسئولیت های کلیدی من در زمینه نقش من در تحقیق و اجرای تکنیک های بینایی رایانه ای مانند برآورد ژست ، تقسیم بندی معنایی ، تشخیص حرکات و تشخیص ویژگی های صورت است. همه تکنیک های ذکر شده بر روی دستگاه های تلفن همراه اجرا می شوند.
تکنیک
در زیر تکنیک های مختلف بینایی رایانه ای وجود دارد که من با استفاده از راه حل های یادگیری عمیق در شش ماه گذشته پیاده سازی کرده ام.
< p> در برخی موارد ، من مدلهایی را که استفاده کرده ام آورده ام: من با استفاده از راه حل تحقیقاتی مانند Stacked Hourglass ، Convolutional Pose Machines (CPM) و Posenet ، برآورد ژست را پیاده کردم.اگر شما یک متخصص یادگیری ماشین هستید ، احتمالاً از برخی از ابزارهایی که در زیر به آنها اشاره شده است مطلع هستید. برای کسانی که به تازگی وارد حوزه هوش مصنوعی شده اند ، ابزارهای ذکر شده توسط دانشمند داده ، محققان ML و مهندسان ML به طور یکسان استفاده می شود.
اینها ابزارهایی هستند که من به صورت روزانه از آنها استفاده می کنم.
< uli> TensorFlow: یک پلتفرم منبع باز برای پیاده سازی ، آموزش و استقرار مدلهای یادگیری ماشین.مهندسی نرم افزار
 عکس توسط کوین کو در Unsplash
عکس توسط کوین کو در Unsplash قبلاً مهندسی نرم افزار را یک مهارت می دیدم ، اما همانطور که در حرفه خود پیشرفت کرده ام ، به این حقیقت رسیده ام که مهندسی نرم افزار بیشتر یک عمل است.
مهندسی نرم افزار نرم افزاری مهارتی نیست که بتوانید آن را در سه ماه به دست آورید ، اما این متدولوژی است که با سالها تجربه در توسعه برنامه های نرم افزاری توسعه می دهید.
بنابراین ، به عنوان یک مهندس یادگیری ماشین ، من روزانه مهندسی نرم افزار را تمرین می کنم. به طور خاص ، من جنبه هایی از اصول مهندسی نرم افزار را در جریان کار و فرایندهای توسعه خود گنجانیده ام. این ممکن است بسیار به نظر برسد ، اما ساختن برنامه های کاربردی مدرن با یک سیستم یادگیری یکپارچه و تکنیک های ML مستلزم هم افزایی بین پلتفرم ها و ابزارهای مختلف است - همه اینها از زبان های مختلف برنامه نویسی برای نوشتن دستورالعمل های اجرایی استفاده می کنند.
در اینجا موارد زیر آورده شده است. زبانهای برنامه نویسی اصلی که در این شش ماه اخیر استفاده کرده ام:
همچنین دانش عملی HTML ، CSS ، SQL ، Kotlin ، NodeJS ، Flask و غیره را دارم. همه اینها ابزارها و زبانهایی هستند بیش از سه سال مهندسی نرم افزار عمومی را گذرانده اید.
کروناویروس
 عکس توسط engin akyurt در Unsplash
عکس توسط engin akyurt در Unsplash هیچکس نتوانست همه گیری جهانی همه گیر فلج کننده در سراسر جهان را در سال 2020 پیش بینی کرده اند. رول توالت در کشورهای غربی به یک کالا تبدیل شد. تبریک آرنج جایگزین دست دادن شد و کار از راه دور در حال حاضر هنجار جدیدی برای اکثر صنایع مبتنی بر فناوری است.
من فقط یک ماه در نقش فعلی خود بودم که بیماری همه گیر به انگلستان رسید و سپس به قرنطینه رفتیم.
کار از راه دور هیچ تغییری در اهداف استارتاپ ها ، پویایی تیم و بلندپروازی من برای انجام کار ایجاد نکرد. مهندس بینایی رایانه و داشتن یک نقش بسیار مبتنی بر فناوری به این معنی است که می توانم از هر کجا با اتصال به اینترنت کار کنم.
مواردکه به کار از راه دور کمک کرد:
برخی می گویند کار از راه دور یک گزینه دائمی برای کارمندان است. واضح است که خود شرکتها هزینه زیادی در فضای اداری صرفه جویی می کنند و هیچ کمبود محسوسی در بهره وری یا نتایج ارائه شده توسط تیمهای شرکت وجود ندارد.
سخت افزار
هنگامی که در مورد اولین ماه من به عنوان یک کامپیوتر نوشتم ، فضاهای همکاری نزدیک یا کافه ها یک گزینه هستند. مهندس بینایی ، من وظیفه خاصی را که برایم تعیین شده بود ، شامل خرید یک ایستگاه کاری GPU می کردم.
پس از تحقیقات طاقت فرسا و برخی شرکت های ارائه دهنده GPU ، چه در ایالات متحده و چه در انگلستان ، در نهایت یکی خریداری کرد.
در پنج ماه گذشته ، من از منابع محاسبه GPU برای آموزش مدلهای سفارشی برای روزهای متوالی استفاده کرده ام. من همچنین اسکریپت هایی را اجرا کرده ام که به طور همزمان بدون هیچ مشکلی در نتیجه 14 هسته CPU که ایستگاه کاری در اختیار دارد اجرا شده است.
من کمی به تاریخچه GPU ها و نحوه پیدایش آنها علاقه مند شده ام. به عنوان یک متخصص یادگیری عمیق ، من و شما می دانیم که آموزش CNN با GPU با معرفی AlexNet و ظهور شبکه های عصبی پیچیده عمیق شد.
من احتمالاً یک مقاله در مورد تاریخچه GPU و سایر حقایق جالب در مورد استفاده و ویژگی های آنها.
یادگیری/تحقیق
 عکس سفر جاده ای با راج در Unsplash
عکس سفر جاده ای با راج در Unsplash یادگیری در حرفه مرتبط با ML هرگز به پایان نمی رسد. خود حوزه هوش مصنوعی با سرعتی در حال پیشرفت است که در آن همیشه پیشرفتهای جدیدی وجود دارد که باید از آنها آگاه باشید (در حال حاضر انتشار GPT-3 است) یا تکنیکهای جدیدی برای پیاده سازی.
با تأمل در شش ماه گذشته ، واقعاً احساس می کنم هنوز در دانشگاه هستم. پس از اتمام شغل "9-5" ، به خانه باز می گردم تا مقالات تحقیقاتی ، مقاله بنویسم و مدلهای ML را بخوانم.
برای کسانی که به دنبال ورود به حرفه ML هستند ،باید آگاه باشید که انتظارات ناگفته ای وجود دارد ، جایی که فرض بر این است که شما در جریان آخرین تحولات هوش مصنوعی قرار گرفته اید. اکثر مردم انتظار دارند که شما بیشتر از یک فرد معمولی درباره نسخه های جدید برنامه کاربردی هوش مصنوعی اطلاعات داشته باشید.
در حال حاضر ، من قبل از اینکه بتوانم ایده های معماری شبکه عصبی خود را تغییر دهم یا به اصلاح آنها بپردازم ، دانش عملی و نظری زیادی کسب می کنم. زیرمجموعه های DCNN. معمولاً یک دوره تحقیقات گسترده قبل از آنکه حتی به این فکر کنم که به هر نوع پیاده سازی نزدیک شوم ، وجود دارد. برای هر تکنیک جدیدی که من در حال تحقیق یا اجرای آن هستم ، حدود 70 درصد محتوا برای من تازگی دارد.
یادگیری هرگز متوقف نمی شود.
ترس
 عکس توسط Aarón Blanco Tejedor در Unsplash
عکس توسط Aarón Blanco Tejedor در Unsplash اگر به شما بگویم که در شش ماه گذشته توانایی های خود را زیر سوال نبردم ، به شما دروغ می گویم.
این اولین نقش من در زمینه ML است و حتی ترسناک تر این واقعیت است که من اولین استخدام یادگیری ماشین در شرکت هستم.
آیا تا به حال در مورد سندرم ایمپستر شنیده اید؟
احساس ناتوانی و نارسایی که احساس می کنید ، حتی اگر به خوبی کار می کنید. این ترکیبی از شک و تردید در خود ، عدم اعتماد به نفس و کلاهبرداری فکری کاذب است که از موفقیت ها و دستاوردهای شما می کاهد. >
آیا من به اندازه کافی سریع می روم؟ آیا من به اندازه کافی خوب هستم؟ آیا من به اندازه کافی باهوش هستم؟ آیا به اندازه کافی می دانم؟ آیا به اندازه کافی خوب است؟ اگر شکست بخورم چی؟ اگر اشتباه کنم چطور؟ این می تواند یک چیز منفی یا مثبت باشد ، همه چیز بستگی به اقدامات شما و نحوه انتخاب شما برای مقابله با شک و تردید در خود دارد. بازی من ، نه با آن فلج می شوم ، نه از آن ضعیف می شوم.
سندرم Imposter بیشتر از آنچه فکر می کنید شایع است. حتی یکی از بزرگترین ذهن ها نیز از آن رنج می برد. .com
جامعه ML
 عکس توسط Annie Spratt در Unsplash
عکس توسط Annie Spratt در Unsplash آنچه من در خارج از کارم انجام می دهم به همان اندازه مهم است که در محل کار انجام می دهم.
در شش ماه گذشته ، من به طور تصادفی شروع به ایجاد یک نام تجاری شخصی در جامعه AI کردم. از طریق چندین پلتفرم آنلاین مختلف ، می توانم روزانه با صدها تا هزاران نفر تماس بگیرم.
و من فکر می کنم شما می توانید و باید همین کار را انجام دهید.
در زیر خلاصه ای از پلتفرم هایی است که من من برای ایجاد حضور در داخل استفاده می کنمجامعه ML.
متوسط
 تصویر از رسانه طراحی
تصویر از رسانه طراحی محتوای مرتبط با هوش مصنوعی در Medium همواره منبع اطلاعاتی خوبی بوده است ، چه در دوران تحصیلات دانشگاهی و چه در حال حاضر در حرفه من. مقاله های پژوهشی معماری شبکه عصبی ؛ و مقالاتی که توصیه های مفیدی در مورد نحوه انتخاب شغل یا مذاکره درباره حقوق در صنعت هوش مصنوعی ارائه می دهد.
در تابستان سال 2019 ، من تصمیم گرفتم نه تنها مصرف کننده محتوا در رسانه ، بلکه یک خالق نیز باشم. نمی دانستم چه انتظاری دارم ، اما یک هدف را در نظر داشتم.
هدف من این بود که از Medium به عنوان ابزاری برای تقویت دانش و اطلاعاتی که در طول مطالعات و پروژه هایم به دست آورده بودم استفاده کنم. متوسط برای من در آن زمان نوعی حفظ دانش بود.
متوسط برای من اکنون بستری است که به من امکان می دهد روزانه با هزاران نفر تماس بگیرم. من بیش از 70 مقاله مرتبط با هوش مصنوعی و ML نوشته ام و می بینم که تعداد زیادی از افراد از نوشته های من الهام گرفته اند و در حال یادگیری و برداشتن یک مورد کاربردی هستند.
من (برای برخی دلیل) به عنوان یکی از نویسندگان برتر در موضوعات: هوش مصنوعی ، فناوری و آموزش شناخته شده است. این در واقع افتخاری است که امیدوارم تا آنجا که می توانم آن را حفظ کنم.
 عکس توسط Greg Bulla در Unsplash
عکس توسط Greg Bulla در Unsplash زمانی که برای اولین بار حساب LinkedIn خود را ایجاد کردم به خاطر نمی آورم ، اما آنچه می توانم بگویم این است که از LinkedIn بیشتر از خودم استفاده کرده ام در سال 2020 در مقایسه با سایر سالها.
تعداد قابل توجهی از افراد آثار من را می خوانند و برخی از خوانندگان در مورد مطالب مقاله من س questionsالاتی دارند. LinkedIn یکی از روشهای مرسوم برای دستیابی به من است.
من بیش از همه خوشحالم که به هر س questionsالی پاسخ می دهم و در مورد موضوعاتی که در زمینه تخصص فنی من قرار دارد مشاوره می دهم. تا به امروز ، من تقریباً به بیش از 50 پرسش از افرادی که از طریق LinkedIn با من تماس گرفته اند ، پاسخ داده ام. همچنین مدتی وقت گذاشته ام تا با افراد تماس های ویدئویی داشته باشم. برخی از س questionsالاتی که دریافت می کنم نیاز به پاسخ های گسترده تری دارد.
بیشتر س questionsالاتی که از من می پرسند در مورد بهترین روش های یادگیری ماشین یا روشهای شغلی است. اگرچه من یک متخصص نیستم ، اما خوشحالم که مطالبی را که در طول تحصیل ، تحقیق و تجربیات خود به دست آورده ام به اشتراک بگذارم.
اگر مایل هستید برای من پیام ارسال کنید یا در مورد موضوعات مرتبط با ML صحبت کنید ، در اینجا قابل دسترسی هستم.
مشاوره
در شش ماه گذشته ، من با افرادی که در پروژه ها مشاوره می خواستند ، نشسته ام و در برخی موارد ، برای وقت و تخصص من پرداخت شده است در حال حاضر ، مبلغی که به من پرداخت شده تغییر زندگی نمی کند و به زودی مشاور تمام وقت نمی شوم. اما این واقعیت که افراد فقط برای تخصص من ارزش پولی قائل هستند هنوز برای من دیوانه کننده است.
علاوه بر کار مشاوره ، اخیراً از من دعوت شده استنویسنده فنی کتاب چشم انداز کامپیوتری که قرار است در آینده منتشر شود. باز هم ، به نظر می رسید که این فرصت بیش از حد واقعی باشد ، اما امروز در اینجا هستم ، چند فصل از کتاب منتشر نشده.
جدا از یادگیری و حرفه ام ، نمی توانم پیش بینی کنم که چه فرصت هایی ممکن است با آن برخورد کنم به هر ماه متفاوت است.
YouTube
 عکس Gianandrea ویلا در Unsplash
عکس Gianandrea ویلا در Unsplash من کانال های YouTube AI/ML را تحسین می کنم ، جایی که میزبان موضوعات مرتبط با یادگیری ماشین را آموزش می دهد یا تکنیک های ارائه شده در مقاله های تحقیقاتی را توضیح و پیاده سازی می کند.
و البته ، من یکی از طرفداران پادکست های الکس فریدمن و کانال YouTube. ، آبیشک تاکور و غیره. به زودی ، مطالبی را ارسال می کنم که احساس می کنم برای کسانی که در یادگیری ماشین/یادگیری عمیق شروع می کنند مفید است.
با خیال راحت اینجا را عضو کانال من شوید (پلاگین بی شرمانه).
اشتباهاتی که من انجام داده ام
 ایموجی چشم از iemoji.com
ایموجی چشم از iemoji.com تعداد اشتباهاتی که در این شش ماه انجام داده ام قابل شمارش نیست.
در اینجا چند اشتباه شرم آور" نه چندان زیاد "آمده است. < /p>
همه مرتکب می شوند اشتباهات؛ اشتباهات اجتناب ناپذیر است آنچه مهم است این است که از اشتباهاتی که انجام می دهید درس بگیرید و به یاد داشته باشید که اشتباهات شما را تعریف نمی کند.
مطمئنم که در شش ماه آینده اشتباهات بیشتری مرتکب می شوم.
چشم انداز سال
 عکس توسط Pablò در Unsplash
عکس توسط Pablò در Unsplash و در اینجا ، شش ماه به طور خلاصه.
برای پایان دادن به شش ماه و نزدیک شدن به بقیه سال ، اهدافی را که برای شما تعیین کرده ام با شما به اشتراک می گذارم. برای خودم.
این اهداف عمدتا این است که من را در مسیر پیشرفت شغلی ، شخصی و تحصیلی دنبال کنم. برخی از اهداف ذکر شده مبهم هستند و به احتمال زیاد بعداً آنها را تصحیح می کنم.
ادغام با هوش مصنوعی: چگونه مغز بسازیم -رابط رایانه ای برای ارتباط با Google با استفاده از Keras و OpenBCI
ادغام با هوش مصنوعی: چگونه مغز بسازیم -رابط رایانه ای برای ارتباط با Google با استفاده از Keras و OpenBCI
ایلان ماسک و Neuralink می خواهند یک رابط مغز و رایانه بسازند که بتواند به عنوان لایه سوم مغز عمل کند و به انسان این امکان را بدهد که با Artificial ارتباط همزیستی برقرار کند. هوش.
اما اگر می توانید این کار را انجام دهید؟
در یک شکل (بسیار) محدود ، در واقع می توانید.
سابقه
< p> رابط مغز و رایانه (BCI) به طور گسترده به هر سیستمی اطلاق می شود که ارتباط مستقیمی بین سیستم عصبی و یک دستگاه الکترونیکی برقرار کند. این دستگاه ها ممکن است با جراحی در مغز کاشته شوند یا خارجی باشند. پارادایم های معمولی شامل اجازه دادن به کاربر برای کنترل یک محرک یا صفحه کلید ، اجازه دادن به یک دستگاه برای ارسال داده های حسی به کاربر ، یا ارتباط دو طرفه شامل داده های حسی و کنترل حرکتی (یعنی بازوی مصنوعی که ورودی کنترل موتور را دریافت می کند و داده های حسی را برای فشار ارسال می کند) یا درجه حرارت)از نظر تاریخی ، پروتزهای عصبی انگیزه اصلی تحقیقات BCI بوده است. این شامل اندام مصنوعی برای افراد قطع عضو ، کاشت حلزون شنوایی برای ناشنوایان و تحریک عمیق مغزی برای افرادی است که از تشنج رنج می برند. در حال حاضر ، این دستگاه ها زندگی میلیون ها نفر را بهبود بخشیده است و استفاده گسترده از آنها مزایای دستیابی به ارتباط مستقیم دو طرفه بین مغز و دستگاه های الکترونیکی را نشان می دهد. با این حال ، کاربردهای احتمالی این فناوری بسیار فراتر از مراقبت های بهداشتی است. حتی در حوزه پروتزهای عصبی ، ما می توانیم فراتر از ترمیم تصور کنیم و به افزایش توانایی های خود فراتر از سطوح طبیعی انسان فکر کنیم. اعضای مصنوعی ممکن است روزی به حدی پیشرفت کنند که با هر معیار عینی از همتایان طبیعی خود برتر باشند. این اندام ها ممکن است شبیه اندام های معمولی به نظر برسند ، اما بسیار قوی تر و چابک تر هستند. مثال دیگر می تواند چشم مصنوعی باشد که وضوح بسیار بیشتری نسبت به چشم انسان دارد ، توانایی بزرگنمایی یا کوچک نمایی و مشاهده در طیف UV یا IR را دارد.
با توجه به شناخت ، امکانات حتی جالب تر می شوند. و شکل گیری مهارت یک مطالعه اخیر نشان می دهد که تحریک قسمت های خاصی از مغز باعث بهبود حافظه و به یاد آوردن آن می شود. آزمایش های دیگر موفق شده اند به طور مصنوعی خاطرات را در حیوانات کاشته باشند. به عنوان مثال ، ممکن است بتوان از روشهای این مطالعات برای افزایش توانایی یادگیری سریع یک ابزار استفاده کرد. یا شاید بتوان محرک های عصبی و حسگرهای مختلف را برای ایجاد "واحد پردازش حسابی" ترکیب کرد که بتواند تشخیص دهد که مناطق خاصی از مغز مرتبط با استدلال ریاضی یا منطقی فعال شده و با آنها ارتباط برقرار می کند.
این گسترش این تقویت شناختی است که ایلان ماسک و Neuralink می خواهند دنبال کنند. به گفته ماسک و بسیاری از نظریه پردازان برجسته هوش مصنوعی ، یک مانع کلیدی در پیشرفت فکری بشری نسبت به هوش مصنوعی ، مشکل پهنای باند است: اگرچه رایانه ها و هوش مصنوعی در حال پردازش و تولید دانش سریعتر و بیشتر هستند ، اما ما با محدودیت های فوری و اساسی در توانایی خود روبرو هستیم. برای انجام همین کار ما اطلاعات را در درجه اول از طریق حواس و توانایی تفسیر زبان به دست می آوریم. در زمانی که خواندن و فهمیدن آن به چشم ها و قشر بینایی شما نیاز داردیک جمله واحد ، رایانه می تواند هزاران صفحه متن را اسکن کند. می توان تصور کرد که در چند دهه آینده ، ما ممکن است هوش مصنوعی پیشرفته ای داشته باشیم که روی سخت افزارهای تخصصی نورومورفیک کار می کند ، با مدل های فوق العاده دقیق نحوه کار جهان و توانایی تجزیه و تحلیل و درک میلیون ها سند در عرض چند دقیقه ، تصمیم گیری و استنباط هایی که بسیار فراتر از انسان است. درک مطلب. در جهانی که به طور فزاینده ای به تصمیم گیری های مبتنی بر هوش مصنوعی وابسته است ، ممکن است انسانها در تمام بخشهای تصمیم گیری تجاری ، علمی و سیاسی منسوخ شوند. مغز ما برای بازی شطرنج با تریلیون ها مهره یا درک استراتژی های محاسبه شده که میلیون ها حرکت پیش رو را برنامه ریزی می کند ، تکامل نیافته است. این ترس از این جعبه سیاه فوق العاده است که انگیزه بسیاری از کارهای فعلی در Neuralink ، Kernel و چندین سازمان مرتبط دیگر را ایجاد می کند.
بیشتر تحقیقات پیشرو در فناوری BCI به دنبال به حداکثر رساندن اطلاعات هستند پهنای باند ، معمولاً از طریق روشهای تهاجمی که الکترودها را مستقیماً در مغز یا اعصاب کاشته می شود. با این حال ، روشهای غیر تهاجمی ، به ویژه الکتروانسفالوگرافی (EEG) و الکترومیوگرافی (EMG) به طور معمول با موفقیت قابل توجهی استفاده می شود. اینها شامل قرار دادن الکترودهایی روی سطح سر (EEG) یا پوست بالای عضلات (EMG) برای اندازه گیری فعالیت الکتریکی تجمع یافته در زیر است. جزئیات این داده ها پایین است و فاصله زیادی با سطح دقت و پهنای باند دارد که در نهایت برای تحقق اهداف بلندپروازانه تحقیقات BCI مورد نیاز است. با این وجود ، BCI های دارای EEG/EMG به موفقیت های باورنکردنی مانند کنترل هواپیماهای بدون سرنشین ، بازی های ویدئویی و صفحه کلیدها با فکر دست یافته اند ، و آنها نگاه کوچکی به امکاناتی که تحقیقات بیشتر ممکن است باز کند ، ارائه می دهند. علاوه بر این ، چندین شرکت مانند Cognixion و Neurable در حال بررسی برنامه های کاربردی BCI های مبتنی بر EEG هستند و با پروژه های هیجان انگیز زیادی که در دست انجام است ، بودجه و پشتیبانی قابل توجهی دریافت کرده اند.
مرور کلی
در این پروژه ، ما یک ارتباط مستقیم بین سیستم عصبی خود و یک عامل هوش مصنوعی خارجی ایجاد کنید. این نماینده ممکن است هر چیزی باشد که بتوانید برای آن یک API دریافت کنید: Google Assistant ، Siri ، Alexa ، Watson ، و غیره. خدمات مانند دیکشنری یا YouTube نیز واجد شرایط هستند ، اما اینها برنامه ها را به درخواستهای محتوا محدود می کند تا درخواستهای عمومی.
برای اهداف این پروژه ، ما مستقیماً از جستجوی Google پرس و جو می کنیم زیرا بیشترین انعطاف پذیری را دارد و راحت ترین راه برای تنظیم است. پس از اتمام ، شما باید بتوانید تعداد کمی از اصطلاحات را در Google به سادگی در مورد آنها جستجو کنید.
تکنیکی که ما استفاده می کنیم از سیگنال های عصبی ایجاد شده توسط مغز شما در فرایند فراخطی استفاده می کند. این "مونولوگ داخلی" است که هنگامی که به آرامی و عمداً می خوانید یا فکر می کنید در داخل سر شما اتفاق می افتد. ممکن است متوجه شده باشید که هنگام سکوت خواندن این کار را انجام می دهید ، گاهی اوقات تا جایی که فک و زبان خود را با ظرافت حرکت می دهید بدون اینکه حتی متوجه شوید. همچنین ممکن است هنگام دریافت نکات مربوط به SAT ، MCAT ، GRE یا سایر آمادگی های استاندارد استاندارد با این مفهوم برخورد کرده باشید. به داوطلبان آزمون توصیه می شود از فراخوانی خودداری کنند زیرا این یک عادت بد است که سرعت خواندن را کند می کند.زیرا مغز سیگنال هایی را به حنجره شما ارسال می کند که مربوط به کلماتی است که شما فکر می کنید ، حتی اگر قصد ندارید آنها را با صدای بلند بیان کنید. با قرار دادن الکترودهایی روی صورت بر روی اعصاب حنجره و فک پایین ، می توانیم سیگنال های مربوط به کلمات خاص را ضبط کرده و از آنها برای آموزش مدلهای یادگیری عمیق که بین کلمات مختلف تشخیص می دهند استفاده کنیم. به عبارت دیگر (بدون استفاده از کلمات کلیدی) ، ما می توانیم تشخیص دهیم که شما در مورد یک کلمه خاص به سادگی از عملکرد آن فکر می کنید.
 مغز و اعصاب حنجره
مغز و اعصاب حنجره این فناوری محدودیت هایی دارد و به هیچ وجه مناسب یا آماده استفاده عملی نیست. با این حال ، از اولین تظاهرات خود در دنیای واقعی دو سال پیش توسط MIT Media Lab ، با موفقیت در دستگاه هایی استفاده می شود که به کاربران امکان می دهد در هنگام بازی شطرنج ریاضیات ، تماس های تلفنی ، سفارش پیتزا و حتی دریافت کمک را انجام دهند.
 هدست آزمایشگاهی MIT Media AlterEgo
هدست آزمایشگاهی MIT Media AlterEgo SETUP & MATERIALS
< p> ابزار سخت افزاری اولیه مورد نیاز یک برد OpenBCI Ganglion است. گزینه های سخت افزاری دیگری نیز وجود دارد ، اما من OpenBCI را به عنوان یکی از بزرگترین انجمن های توسعه دهندگان برای پشتیبانی یافتم. قیمت شما حدود 200 دلار است ، اما با توجه به چیزهای باورنکردنی که می توانید با آن بسازید ، ارزشش را دارد. برد و الکترود OpenBCI
برد و الکترود OpenBCI علاوه بر برد ، به الکترودها و سیم ها نیز نیاز دارید. مجموعه ای از الکترودهای فنجان طلا و ژل الکترود باید 50 دلار هزینه داشته باشد و خوب کار کند. متناوبا ، می توانید یک کیت استارت OpenBCI کامل ، که شامل برد و چند نوع الکترود خشک و همچنین یک هدبند الکترود است ، به قیمت 465 دلار تهیه کنید. این کمی گران است ، بنابراین تنظیم جام طلا کاملاً خوب است. با این حال ، اگر قصد دارید با سایر کاربردهای BCI ، مانند VR (آموزش استفاده از Unity VR به زودی!) آزمایش کنید ، هدبند و الکترودهای خشک تجربه بسیار بهتری را ایجاد می کنند.
Biosensing Starter Kit
OpenBCI همچنین تخته 8 و 16 کانال را ارائه می دهد. اینها کیفیت داده بالاتری را ارائه می دهند ، اما 4 کانال Ganglion برای این پروژه مناسب است. ترمینال خود را باز کنید و دستور زیر را تایپ کنید:
python3 --version
اگر پایتون ندارید یا نسخه قدیمی تری دارید ، وارد کنید: pre> $ sudo apt-get update $ sudo apt-get install python3.6
اکنون ، فهرست pyOpenBCI را بارگیری یا کلون کنید.
فهرست را به مخزن تغییر دهید و دستور زیر را برای نصب بسته های پیش نیاز اجرا کنید: < /p>
$ pip install numpy pyserial bitstring xmltodict request bluepy
اکنون آماده نصب pyOpenBCI
$ pip install pyOpenBCI
برای مشاهده هستید برخی از اقدامات ، تغییر دایرکتوری به pyOpenBCI/Examples و یافتن print_raw_example.py. این فایل را با ویرایشگر کد مورد علاقه خود باز کنید و تغییرات زیر را در خط 7 ایجاد کنید:
board = OpenBCICyton (daisy = False)
باید به:
<تغییر کرد pre> board = OpenBCIGanglion (mac = '*')این به pyOpenBCI اجازه می دهد تا ماژول های مناسبی را برای برد خاصی که ما استفاده می کنیم بکار گیرد.
اکنون ، برد خود را روشن کنید. < /p>
در رایانه خود ، از فهرست Examples در ترمینال ، دستور زیر را تایپ کنید:
$ sudo python print_raw_example
بوم !! اکنون ترمینال شما باید با جریان داده های ورودی خام از روی صفحه پر شود.
ثبت سیگنال
اکنون که می توانیم سیگنال های خام را بدست آوریم ، می توانیم شروع کنیمطراحی و ساخت خط لوله داده برای شروع ، ابتدا باید داده های خام را به جریان LSL تبدیل کنیم. LSL به لایه Streaming Stream اشاره دارد و یک پروتکل است که در مرکز Swartz برای علوم اعصاب محاسباتی در UC San Diego توسعه یافته است تا ضبط و تجزیه و تحلیل جریان داده های زنده را تسهیل کند. LSL داده های EEG ما را بر روی میزبان محلی پخش می کند ، جایی که می توان آن را توسط برنامه های دیگر یا اسکریپت ها دریافت کرد.
تغییر فایل lsl_example.py در pyOpenBCI/Examples برای حذف جریان AUX ، که ما این کار را انجام می دهیم. نیازی نیست ، یک جریان نشانگر اضافه کنید:
ما اکنون باید یک مجموعه آزمایشی تعریف کنیم که داده ها را در فرم مورد نظر ما ضبط کرده و برای استفاده بیشتر ذخیره کند. ما می خواهیم آزمایش مجموعه ای از داده های سری EEG سری زمانی را که در فواصل جدا شده تولید می شود ، ایجاد کند که هر فاصله مربوط به زیر صداگذاری یک کلمه است. برای دستیابی به این هدف ، می توانیم آزمایشی را اجرا کنیم که یک جلسه ضبط با فواصل N را شروع می کند و هر فاصله T ثانیه طول می کشد. همه نمونه ها در یک بازه زمانی مشخص شده با شاخص فاصله و کلمه خاصی که به کاربر دستور داده می شود تا زیر صدا را بیان کند ، ذکر می شود.
فایل lsl-record.py از neurotech-berkeley به عنوان یک نقطه شروع خوب عمل می کند. مطابق با تنظیمات تعریف شده ما فایل را اصلاح کنید:
شما می توانید اصطلاح BankBank (خط 64) را برای آزمایش ترکیب های مختلف کلمات در زمینه های مختلف تنظیم کنید. همچنین می توانید مدت زمان پیش فرض (خط 12) را قبل از هر جلسه تنظیم کنید.
اکنون زمان قسمت سرگرم کننده است! الکترودها را به برد خود وصل کنید:
 4 کانال چپ EEG ، راست 2 است کانال ها به حالت اولیه هستند
4 کانال چپ EEG ، راست 2 است کانال ها به حالت اولیه هستند آنها را با تنظیمات زیر روی صورت خود بچسبانید:

یک مکان آرام برای نشستن پیدا کنید و خطوط زیر را در پایانه های جداگانه وارد کنید:
//ترمینال 1: داده های خام را به LSL تبدیل کرده و آنها را پخش می کند $ sudo python lsl_example
//ترمینال 2: جریان داده LSL را می خواند و آزمایش را اجرا می کند $ sudo python lsl_record
توجه: ما به عنوان sudo اجرا می کنیم تا اسکریپت بتواند آدرس MAC صفحه را تشخیص دهد
این باید یک جلسه ضبط با مدت زمان مشخص را آغاز کند. با یک کلمه تصادفی از بانک اصطلاح از شما خواسته می شود تا در فاصله های 2 ثانیه ای صدای ضعیفی را بیان کنید. جلسات ضبط ممکن است ناراحت کننده و خواب آور باشد ، بنابراین بهتر است چندین جلسه کوچک با وقفه بین آنها انجام دهید. علاوه بر این ، در صورت بروز اختلالات مکرر (به عنوان مثال حرکات ناگهانی یا کم صدا کردن کلمه نادرست) ، تنظیم تجربی ما ممکن است منجر به کیفیت داده های ضعیف شود.
شما می توانید یک تنظیم انعطاف پذیرتر با گزینه ای برای ضربه زدن به کلید طراحی و اجرا کنید. فواصل فعلی و قبلی را با مشاهده مزاحمت حذف می کند. راه حل دیگر این است که چندین جلسه کوچک انجام دهید و داده ها را در پایان ترکیب کنید ، جلسات را با اختلالات بیش از حد کنار بگذارید. برخی از سر و صدا اجتناب ناپذیر است ، و نیازی نیست که زیاد انتخابی باشید زیرا مدل با افزایش تعداد نمونه ها انعطاف پذیرتر می شود.
برای نتایج مطلوب ، باید حداقل 1000 نمونه با کیفیت بالا برای هر کلمه در بانک کلمات شما. مناسب است تا داشته باشدقالب زیر: شاخص ها از 1 تا NumIntervals ، که مجموع SessionDuration/2 بر تعداد کل جلسات است
فایل های CSV خود را با استفاده از numpy به پایتون وارد کنید. شما باید تمام داده های خود را در Numray خط 6 x ndarray در اسکریپت خود بارگذاری کنید.
اولین قدم فیلتر کردن داده ها برای حذف نویز خارج از فرکانس های مورد علاقه ما است. به نوارهای زیر: برای فرکانسهای بین 4 هرتز تا 100 هرتز ممکن است منطقی به نظر برسد ، اما با شکست مواجه می شود زیرا 60 هرتز فرکانس شبکه برق است (ممکن است بر اساس کشور متفاوت باشد) ، که احتمالاً منبع قابل توجهی از نویز است. برای نتایج مطلوب ، باید بین 4 هرتز تا 50 هرتز فیلتر کنیم.
ما می توانیم از فیلتر Scipy's Butterworth برای انتخاب محدوده فرکانسی که می خواهیم حفظ کنیم استفاده کنیم. یک فیلتر با کد زیر تعریف کنید:
سپس ، یک ستون زمانبندی ایجاد کنید (همانطور که ما مجموعه داده های متعددی را ترکیب کرده و نشانهای زمانی اصلی را نامعتبر کرده ایم) و فیلتر را در هر کانال اعمال کنید:
پس از فیلتر شدن ، از کد زیر برای بازسازی داده های خود در یک آرایه سه بعدی ndarrray با ابعاد IntervalLength x ChannelCount x IntervalCount استفاده کنید.
آنچه ما با کد فوق به طور م doneثر انجام داده ایم ، تبدیل داده های سری زمانی به داده های تصویر است به ممکن است کمی عجیب به نظر برسد ، اما می توانید هر 2 ثانیه را به عنوان یک تصویر در نظر بگیرید ، هر پیکسل مربوط به مقدار سیگنال به دست آمده در مختصات خاص (channelNumber ، lineNumber) است. به عبارت دیگر ، ما مجموعه ای از تصاویر IntervalCount داریم که اندازه هر یک از آنها IntervalLength x CannelCount است.
 اولین 120 نقطه داده در فاصله EEG
اولین 120 نقطه داده در فاصله EEG این تکنیک ، که توسط جاستین الوی در پروژه ای مشابه نشان داده شد ، فوق العاده قدرتمند است زیرا به ما اجازه می دهد داده های سری زمانی را طوری درمان کنیم که گویی داده های تصویری بودند که به ما اجازه می داد از قدرت بینایی رایانه و شبکه های عصبی کانولوشنال (CNN) استفاده کنیم. شما حتی می توانید یک فرعی خاص را با ترسیم آن به صورت تصویر تجسم کنید. تعیین فرکانس هایی که باید به دنبال آن باشد.
اکنون ما آماده شروع ساخت CNN هستیم. از آنجا که ما فقط 1 بعد رنگ داریم ، می توانیم از یک CNN 1 بعدی با ابعاد ورودی IntervalLength و ChannelCount استفاده کنیم. ممکن است با پارامترها و معماری های مختلف آزمایش کنید. من بر روی یک لایه متحرک تک ، دو لایه کاملاً متصل و دو لایه جمع کننده مستقر شدم.
برای تجزیه و تحلیل دقیق تر CNN های تک بعدی و نحوه کاربرد آنها در داده های سری زمانی ، به این مقاله توسط نیلس مراجعه کنید. آکرمن.
ما در حال حاضر مدلی داریم که باید بتواند فاصله ای از داده های EEG را با یک کلمه خاص در بانک کلمات شما مطابقت دهد.
بیایید ببینیم که چقدر خوب عمل می کند. مدل را روی داده های آزمایش اعمال کنید و نتایج پیش بینی شده را با نتایج واقعی مقایسه کنید.
# مدل آزمایش y_preditted = model.predict (X_test)
بادو کلمه در عبارت بانک ، من توانستم به 90 درصد دقت دست پیدا کنم. همانطور که انتظار می رفت ، دقت با کلمات اضافی کمی کاهش یافت ، با 86٪ برای سه راه و 81٪ برای چهار جهت.
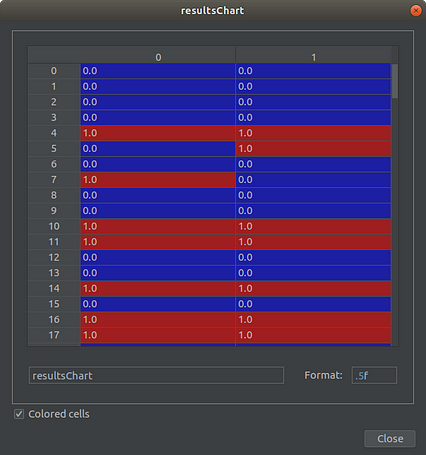 نمونه نمودار حقیقت از طبقه بندی دو کلمه ای. چپ واقعی است ، راست پیش بینی شده است > pp یک راه ممکن برای افزایش اندازه اصطلاح بانک بدون به خطر انداختن دقت ، ایجاد یک "اصطلاح درخت" سلسله مراتبی با پرس و جوهای چند کلمه ای است. سپس می توانید ابتدا جستجوی عمقی را روی درخت انجام دهید - هر لایه کلمات فقط با لایه های مشابه در زیر درخت مشابه با دیگران مقایسه می شود - تا بهترین مطابقت را پیدا کنید.
نمونه نمودار حقیقت از طبقه بندی دو کلمه ای. چپ واقعی است ، راست پیش بینی شده است > pp یک راه ممکن برای افزایش اندازه اصطلاح بانک بدون به خطر انداختن دقت ، ایجاد یک "اصطلاح درخت" سلسله مراتبی با پرس و جوهای چند کلمه ای است. سپس می توانید ابتدا جستجوی عمقی را روی درخت انجام دهید - هر لایه کلمات فقط با لایه های مشابه در زیر درخت مشابه با دیگران مقایسه می شود - تا بهترین مطابقت را پیدا کنید. GOOGLE SEARCH
< p> ما در حال حاضر تمام قطعات لازم برای پرس و جو از Google با استفاده از BCI شما را داریم. یک نگاشت بین فرعی و درخواستهای خاص تعریف کنید و تماس مناسب را انجام دهید:و….
برای انجام درخواستهای زنده همانطور که فکر می کنید ، اسکریپت lsl_record.py را به عنوان یک ماژول اصلاح و وارد کنید. سپس می توانید آن را برای خواندن جریان LSL در پاسخ به ورودی کاربر برای یک فاصله 2 ثانیه ای صدا کنید.
همین! اکنون می توانید بدون گفتن یا تایپ یک کلمه در گوگل جستجو کنید.
نتیجه گیری
با یک بانک اصطلاح سه یا چهار کلمه ای نمی توانید کارهای زیادی انجام دهید (مانع اجرای اصطلاح -درختی که قبلاً ذکر شد). گذراندن همه این مراحل برای جستجوی مسیرها به نزدیکترین پمپ بنزین کمی پیچیده تر از جستجوی گوگل در حالت عادی است. با این وجود ، مهم است که در نظر بگیریم که پیشرفت های بیشتر در این فناوری به کجا می تواند منجر شود. ما می توانیم یک نسخه بهبودیافته و کمتر آشکار از این دستگاه را تصور کنیم ، نه چندان متفاوت از آنچه تیم MIT قبلاً داشته است ، که برای ناوبری ، جستجوهای وب ، پیام های متنی ، مدیریت خانه هوشمند یا هر تعداد کارهای معمول استفاده می شود. وقتی با قدرت بهبود دستیارهای هوش مصنوعی که قادر به تفسیر وابسته به زمینه هستند ، ترکیب شود ، امکانات حتی بیشتر گسترش می یابد. تحقیقات در حال انجام در شرکت ها و آزمایشگاه های دانشگاه در سراسر جهان است. ارتباطات تله پاتی ، هوش مافوق بشری ، حواس اضافی ، تجربیات شبیه سازی شده ، دیجیتالی شدن آگاهی انسان و ادغام با هوش مصنوعی همگی قابل تامل هستند. در صورت تحقق این امکانات ، آنها فقط ارتباط ما با فناوری را دوباره تعریف نمی کنند: آنها معنای انسان بودن را دوباره تعریف می کنند.
منابع
موارد زیر لیستی از منابع است و سازمانهایی که در تکمیل این پروژه و به طور کلی در یادگیری BCI مفید بودم. من می خواهم به ویژه از تیم AlterEgo در آزمایشگاه رسانه ای MIT به عنوان الهام بخش اصلی این پروژه و همچنین آقای آلوی و NeuroTech Berkeley برای کد قبلی و کمک های آموزشی آنها در جامعه BCI قدردانی کنم. علاوه بر این ، می خواهم از استادان دانشگاه کالیفرنیا ، دیویس ، به ویژه دکتر ایلیاس تاگکوپولوس ، دکتر کارن موکسون و دکتر ارکین سکر ، برای کمک و پشتیبانی مداوم تشکر کنم.

سرانجام ، من می خواهم فریاد بزرگی به صدا در آورمجوامع رو به رشد BCI/Neurotech که حمایت ، منابع و اشتیاق بی پایان برای آینده ارائه کرده اند.
اگر مایل به بحث بیشتر یا ارتباط هستید ، لطفاً با LinkedIn
تماس بگیرید.چرا دید رایانه ای پیگیری جریان مردم بازار بزرگی خواهد بود
چرا دید رایانه ای پیگیری جریان مردم بازار بزرگی خواهد بود
 ردیابی لیزری با چگالی در بالای در ورودی
ردیابی لیزری با چگالی در بالای در ورودی همانطور که قبلاً نوشتم معتقدم که Computer Vision به عنوان یک رابط انسان و کامپیوتر به عامل اصلی تبدیل می شود (1) زیرا حسگرها و دوربین ها به ما در درک دنیای فیزیکی کمک می کنند.
در مورد "اینترنت اشیا" مطالب زیادی در رسانه ها وجود دارد که معنای آن را از دست داده است و به دلایل عجیبی بسیاری از آنها به عنوان یک دست کوتاه برای پوشیدنی ها شناخته می شود. پوشیدنی ها به وضوح یک بازار مهم هستند ، اما برای من یک مورد کاربرد گسترده تر این است که اشیاء واقعی را وارد دنیای محاسبات کنیم و مکانیزمی بهتر از Computer Vision وجود ندارد.
به همین دلیل امروز من بسیار هیجان زده هستم سرانجام می توانم در مورد Density ، شرکتی که من 4 میلیون دلار (2) تأمین مالی کردم به همراه Jason Calacanis (ما در هیئت مدیره با هم همکاری می کنیم! همکاری و کار در جهت این هدف مشترک بسیار عالی بود) و با جاناتان تریست در Ludlow Ventures ، آمیت کاپور در Dawn Patrol و چند نفر دیگر.
همانطور که می توانید از تصویر Giphy در بالا جمع آوری کنید ، Density به طور ناشناس حرکت افراد را در حین حرکت در فضاهای کاری دنبال می کند. این یک دستگاه کوچک و زیبا است که در ورودی ها قرار دارد و "افراد ناشناس را به عنوان یک سرویس ردیابی می کند." در ابتدایی ترین حالت خود ، سوابق ساده ای از ورود و خروج از طریق درها (افرادی که به داخل و خارج حرکت می کنند) ایجاد می کند و هر حرکت به یک رکورد در پایگاه داده تبدیل می شود که می تواند در زمان واقعی قابل ردیابی باشد.
موارد اولیه استفاده این اطلاعات ساده واضح است.
اما همانطور که ممکن است از Giphy بالا جمع آوری کنید ، مورد استفاده ساده با ظرافت محلول Density بسیار افزایش می یابد. نرم افزار و بینایی رایانه زمانی تشخیص می دهد که انسان از کنار لیزر عبور می کند و می تواند حرکات دیگر مانند باز شدن درها یا اجسام دیگر (مثلاً سگها) را فیلتر کند.
هر انسانی به شکل چند ضلعی اسیر شده است در یک لحظه دقیق در زمان همانطور که او در اتاق حرکت می کندهر حرکت کوچک به یک ردیف جدید در پایگاه داده با مختصات و توالی زمانی تبدیل می شود. بنابراین یک انسان واحد که از یک اتاق عبور می کند ، البته می تواند هزاران ردیف در یک پایگاه داده ایجاد کند و برنامه های کامپیوتری می توانند از این داده ها معنا پیدا کنند و الگوریتم های یادگیری ماشین البته می توانند تصمیمات آگاهانه ای را در مورد مواردی مانند "یافتن راه" قرار دادن علائم ، شروع کنند. جایی که خطرات جمعیت ممکن است ایجاد شود ، و غیره. به اعتقاد ما ارزان و ناشناس منجر به ایجاد یک بازار گسترده با برنامه هایی می شود که از بسیاری موارد استفاده پشتیبانی می کند. تراکم به سادگی بستر داده و تجزیه و تحلیل است. هدف ما این است که به طور گسترده هزینه های ضبط جریانات مردم را کاهش دهیم و پتانسیل نامحدودی را برای سازمانها ایجاد کنیم تا بتوانند این امر را درک کرده و بینش هایی را طراحی کنند که به برنامه ریزی بهتر فضاها کمک می کند.
البته اگر سازمانی سنسورهای تراکم را خریداری کند ، داده ها به طور گسترده تری در بازار موجود نیست مگر اینکه آنها تصمیم به اشتراک گذاری با دیگران بگیرند. استفاده اولیه از Density تنها یک سازمان خواهد بود ، اما ما فکر می کنیم به احتمال زیاد با گذشت زمان سازمان ها در شرایط محدود و کنترل شده تصمیم به اشتراک گذاری اطلاعات بین شرکت ها خواهند گرفت.
چرا تراکم؟
سرمایه گذاری این پایان نامه برای من اعتقاد من به بینایی رایانه ای را به عنوان ورودی/خروجی نسل بعدی (3) همراه با تز من مبنی بر این که معضل نوآور یا اقتصاد تورم زا ، بزرگترین موفقیت را در اینترنت ایجاد می کند (4).
امروزه راه حل های ردیابی مردم بسیار گران هستند و بیشتر در محیط های خرده فروشی استفاده می شوند. هزینه ها تا حد زیادی پذیرفته شده است و ما فکر می کنیم که این امر به طور گسترده ای تغییر خواهد کرد.
این تیم بر ناشناس ماندن اصرار داشت زیرا معتقد است دستگاههای ردیابی کم هزینه و در دسترس در دسترس نباید هویت افراد را ثبت کنند. ، که هم پذیرش را محدود می کند و هم هزینه ها را به طور چشمگیری افزایش می دهد. باید اعتقاد داشته باشم که با تیمی از بنیانگذاران بسیار درخشان ، بسیار رقابتی و بسیار پرشور ملاقات کرده ام که ایده ای برای محصولی دارند که می تواند بازار را متحول کند.
من به دنبال کسی هستم که تقریباً مأموریت برای دیدن محصول در بازار بیش از کسب درآمد سریع است و من به دنبال بنیانگری هستم که صرفه جو ، مبتکر و دارای احساس قوی نسبت به آنچه به طور منحصر به فرد در مورد اشتباهات بازار و چگونگی آن معتقد است ، باشد. می توان آن را برطرف کرد.
من همیشه به مردم می گویم مهم این است که چه کسی شما را معرفی می کند. من با دوستم جاناتان تریست در لادلو صحبت می کردم و به او گفتم که کمی وقت آزاد کرده ام و به دنبال شرکتی در مراحل اولیه هستم که از نظر فنی به عقب بازگردد. ما در سال گذشته چند معامله انجام داده بودیم ، بنابراین می خواستم بدانم که او اخیراً چه چیزی دیده است. جمع آوری سرمایه و من متنفرمملاقات با افراد دیر در یک فرایند.

از اولین ملاقاتی که من با بنیانگذار و مدیرعامل - اندرو فرح - و تیم او در گروه سیراکوز داشتم ، می دانستم که آنها بینش ، خلق و خو و انگیزه های مناسبی برای ایجاد این بازار دارند.
من گروهی از آنها را آوردم بلافاصله برای ملاقات با بقیه شرکای خود به LA رفتم. ما البته یک بحث داخلی سالم داشتیم که آیا این دستگاه از دقت کافی برخوردار است زیرا در ابتدا به مادون قرمز متکی بود و نمی توانست با دقت کافی ردیابی کند. دوربین های ویدئویی راهی بودند و تقاضای ناشناس ماندن در مقابل راه حل هایی که می توانند به امنیت /شناسایی کمک کنند.
در نهایت به این نتیجه رسیدیم که تیم های فوق العاده با استعدادی مانند Density تصمیمات درستی در زمینه طراحی محصول می گیرند و ما نباید محصولات امروزی را در برابر قابلیت های تیم برای انتخاب محصول مناسب انتخاب کرد ، زیرا آنها از نمونه اولیه به محصول نهایی رسیدند.
و البته ظرف چند ماه پس از جمع آوری سرمایه ، تیم طراحی محصول را کامل کرد و از مادون قرمز به سمت لیزر دور شد و کارایی ، جمع آوری داده ها و دقت را در حالی که هزینه ها ثابت نگه داشته شد ، بهبود بخشید. t دریافت کنید بیش از حد به مشخصات دقیق محصول امروز متصل شده اید - شما بیشتر به دنبال این هستید که چگونه آنها انتخابهای طراحی خود را تا به امروز انجام داده اند ، چه گزینه های دیگری را در نظر گرفته اند و چگونه به نتایج اولیه خود رسیده اند. شما همچنین انعطاف پذیری ذهنی آنها را در نظر گرفتن راه حل های جایگزین آزمایش می کنید تا بدانید در نهایت آنها بر اساس داده هایی که در سفر خود جمع آوری می کنند با بالاترین کیفیت تصمیم گیری می کنند.
من نمی توانم به این اندازه تأکید کنم - سرانجام سرمایه گذاران برای تصمیم گیری های سخت باید به تیم های موسس اعتماد کنند زیرا تیم روز به روز در سنگر زندگی می کند و سرمایه گذاران می توانند خود را فریب دهند که فکر می کنند از طریق شهود یا ملاقات با 10 شرکت در یک فضا ، پاسخ درست را می دانند. هیچ چیز تیم را بر زمین نمی زند و اگر به آنها در برقراری تماس های سخت اعتماد ندارید - پس آنها را پشت سر نگذارید. نقش ما شریک نبرد است. وظیفه ما این است که مطمئن شویم تیم شما سخت ترین سالات را از خود می پرسد. در نهایت ، رای با شما است.
چه تراکم بعدی؟
امروز ما به طور رسمی اعلام می کنیم که محصول در دسترس اولین شرکت ها و توسعه دهندگانی است که آن را سفارش می دهند (ما محدودیت داریم موجودی) و به طور کلی در سه ماهه اول سال آینده در دسترس خواهد بود. این یک محصول مصرفی نیست - برای افرادی با قابلیت های فنی است. ما آن را در بتا خصوصی در 6 ماه گذشته با شرکت هایی مانند Uber ، با دانشگاه های بزرگ ، با یک شرکت هواپیمایی بزرگ و بسیاری از شرکت های دیگر داشته ایم.
یک ویدیوی کلی 1 دقیقه ای عالی در اینجا وجود دارد و در زیر تعبیه شده است. :
اگر می خواهید مشارکت داشته باشید یا فقط علاقه مند به یادگیری بیشتر هستید ، لطفاً از وب سایت Density دیدن کنید.
ضمیمه
(رسانه هنوز اینطور نیست به من اجازه دهید پیوندهایی در داستان داشته باشم که زبانه های جدیدی باز کند ، بنابراین اکثر پیوندهای خود را به عنوان ضمیمه قرار می دهم تا حواس خواننده را پرت نکنم.با کلیک کردن روی داستان اصلی)
3. معضل مبتکران و اقتصاد تورمی و نحوه راه اندازی آنها در استارتاپ ها.
4. چگونه سرمایه گذاری کنم؟
هوش مصنوعی-آموزش بینایی رایانه پایتون با OpenCV
هوش مصنوعی-آموزش بینایی رایانه پایتون با OpenCV
 AI-چشم انداز رایانه پایتون آموزش با OpenCV
AI-چشم انداز رایانه پایتون آموزش با OpenCV رایانه در پایتون چیست؟
بینایی رایانه ای زمینه ای از چندین رشته است که به نحوه درک رایانه ها از تصاویر/فیلم های دیجیتال در سطح بالا اهمیت می دهد. این تلاشی برای خودکارسازی وظایفی است که سیستم بینایی انسان قادر به انجام آن است. این یک فرایند کسب ، پردازش ، تجزیه و تحلیل و درک تصاویر دیجیتال و استخراج داده های با ابعاد بالا از دنیای واقعی (برای تولید اطلاعات عددی/نمادین) است.
زمینه های مربوط به دید رایانه ای پایتون: < /p>
برخی از کاربردهای Python Computer Vision:
کامپیوتر پایتون OpenCV چشم انداز
گری برادسکی OpenCV را در Intel در سال 1999 راه اندازی کرد. در حالی که از گستره ای از زبان ها مانند C ++ ، Python و موارد دیگر پشتیبانی می کند ، و OpenCV-Python یک API برای OpenCV است که قدرت پایتون و OpenCV را آزاد می کند API C ++ به یکباره.
برای پایتون ، این کتابخانه پیوندهایی با هدف حل مشکلات بینایی رایانه است. این کتابخانه از NumPy استفاده می کند و تمام ساختارهای آرایه آن به آرایه های NumPy تبدیل می شوند. این بدان معناست که ما می توانیم آن را به راحتی با کتابخانه های دیگر مانند SciPy و Matplotlib (که از NumPy استفاده می کنند) ادغام کنیم.
a. نصب OpenCV در Python
قبل از نصب OpenCV ، مطمئن شوید که Python و NumPy را بر روی دستگاه خود نصب کرده اید.
می توانید چرخ OpenCV را از اینجا (غیر رسمی) بارگیری کنید ، بنابراین شما با DLL Hell مواجه نشوید:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
سپس ، می توانید این فایل را با استفاده از pip:
pip install [path_of_wheel_file]
ب. وارد کردن OpenCV در پایتون
رفتن به IDLE و وارد کردن OpenCV:
همچنین می توانید بررسی کنید که کدام نسخه را دارید:
'3.4.3'
Python Computer Vision - کار با تصاویر
اکنون که ما با موفقیت نصب کردیم OpenCV ، بیایید با آن شروع کنیم.
 کامپیوتر رایانه پایتون-کار با تصاویر
کامپیوتر رایانه پایتون-کار با تصاویر a. خواندن تصاویر در پایتون
برای خواندن یک تصویر ، ما تابع/متد imread () داخلی را داریم.
توجه داشته باشید که قبل از این ، ما به فهرست راهنمای این تصویر منتقل شده ایم.
ما همچنین می توانیم یک مقدار برای یک پرچم ، که دومین آرگومان است-
ما می توانیم اعداد صحیح 1 ، 0 یا -1 را ارسال کنیم.
اگر از یک تصویر تصویر نادرست عبور می کنید ، این خطا به ما نمی دهد ، اما print (img) هیچ کدام را به ما نمی دهد.
بیایید ساختارهای داده پایتون را بازبینی کنیم
ب. نمایش تصاویر در پایتون
تابع/متد cv2.imshow () به ما امکان می دهد تصویری را در پنجره ای که متناسب با اندازه تصویر است نمایش دهیم. اولین آرگومان نام پنجره است- یک رشته ؛ دوم تصویر است.
ما displa را چطور؟تماس با منتظر کلید (0) مفید است. این یک تابع/روش اتصال به صفحه کلید با زمان در میلی ثانیه است. این عملکرد چند ثانیه منتظر یک رویداد صفحه کلید می ماند ، در این صورت ، اگر هر کلیدی را فشار دهیم ، برنامه ادامه می یابد. وقتی صفر را رد می کنیم ، باعث می شویم تا زمان نامحدودی منتظر یک ضربه کلیدی بماند. همچنین می توانیم منتظر کلیدهای خاصی باشیم. cv2.destroyWindow () پنجره خاصی را خراب می کند.
ج. نوشتن تصاویر در پایتون
برای این منظور ما تابع/متد cv2.imwrite () را داریم. آرگومان اول نام فایل است و دومی تصویر ذخیره شده است.
درست
این تصویر را در مقیاس خاکستری با نام "pygray.png" در فهرست فعلی ذخیره می کند. این تصویر در قالب PNG است.
 تصاویر پایتون
تصاویر پایتون د نمایش تصاویر با Matplotlib
ما می توانیم این تصویر را با استفاده از Matplotlib نمایش دهیم.
 رایانه پایتون-نمایش تصاویر با Matplotlib
رایانه پایتون-نمایش تصاویر با Matplotlib طراحی با OpenCV Python Computer Vision
a. رسم خطوط در پایتون
آیا می توانیم حتی با پایتون ترسیم کنیم؟ بیایید با یک خط ساده شروع کنیم. این مختصات شروع و پایان را می گیرد.
 ترسیم خطوط در پایتون
ترسیم خطوط در پایتون ب. رسم مستطیل ها در پایتون
با متد/تابع () مستطیل می توان یک مستطیل رسم کرد. این قسمت گوشه سمت چپ بالا و گوشه سمت راست پایین مستطیل را می گیرد.
نگاهی به Python Heatmap
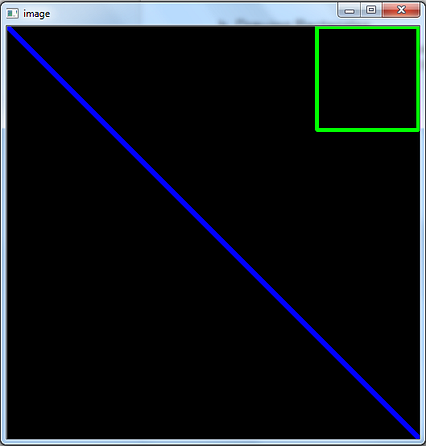 طراحی مستطیل در پایتون
طراحی مستطیل در پایتون ج. رسم دایره ها در پایتون
ما برای این کار متد/تابع () را داریم. این مختصات و شعاع را می گیرد.
بیایید در مورد استدلال های تابع Python
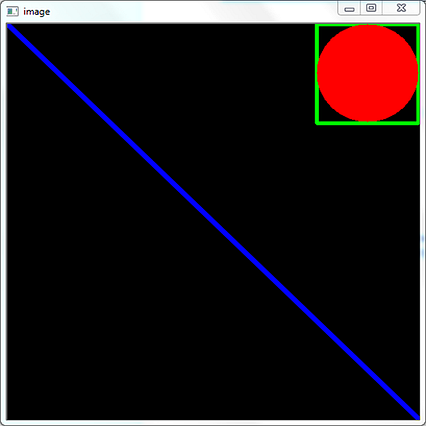 طراحی حلقه ها در پایتون
طراحی حلقه ها در پایتون د. رسم بیضی ها در پایتون
ما می توانیم چندین آرگومان را به بیضی () متد () تابع/محل مرکز (x ، y) ، طول محورها ، زاویه ، startAngle و endAngle منتقل کنیم.
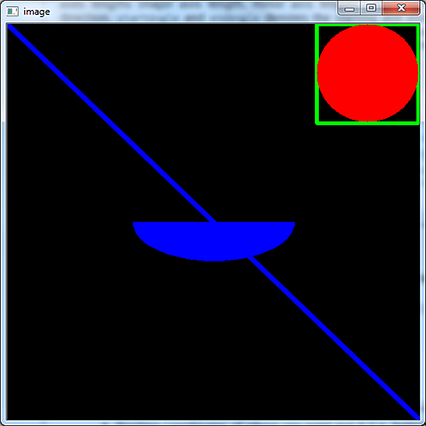 ترسیم بیضی در پایتون.
ترسیم بیضی در پایتون. ه. رسم چند ضلعی در پایتون
روش/تابع () polylines مختصات رئوس را می گیرد.
بیایید فهرست راهنمای پایتون را
 ترسیم چند ضلعی در پایتون
ترسیم چند ضلعی در پایتون f. قرار دادن متن در تصاویر
در نهایت ، بیایید ببینیم چگونه می توانیم متن را به این تصویر اضافه کنیم.
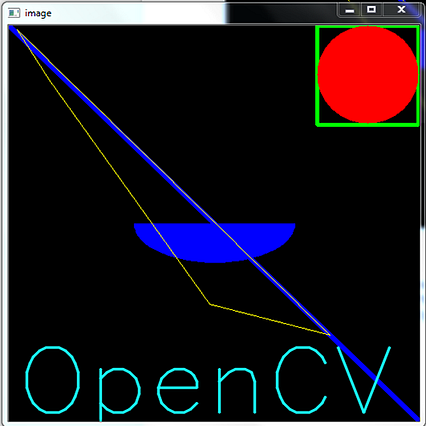 قرار دادن متن در تصاویر
قرار دادن متن در تصاویر عملیات اساسی روی تصاویر
بیایید این را از طریق یک کد نشان دهیم.
نگاهی به Python OrdedDict
درست
بیایید Pythpn عادی عبارات را بازبینی کنیم
 تشخیص چهره ها در دید رایانه ای پایتون
تشخیص چهره ها در دید رایانه ای پایتون می بینید که این یک مربع آبی رنگ کشیده است uare در اطراف صورت در تصویر حالا ، بیایید سعی کنیم چشم های او را تشخیص دهیم.
تشخیص چشم در رایانه پایتون
در حال حاضر ، آخرین موردی که ما می خواهیم در مورد آن بحث کنیم تشخیص چشم است. ما برای این کار از طبقه بندی Haar نیز استفاده می کنیم.
شما باید Python Web Framework
درست
 تشخیص چشم در دید رایانه ای Python
تشخیص چشم در دید رایانه ای Python در اینجا ، می توانید ببینید که سه چشم را تشخیص داده است! یکی از آنها لب های اوست به هر حال ، این بارها دقیق است ، ما به طور تصادفی به یکی از تصاویری برخورد کردیم که استثنا را ایجاد می کند. اگر این اتفاق برای شما افتاده است ، در نظرات زیر به ما بگویید.
بنابراین ، همه اینها در آموزش چشم انداز رایانه پایتون بود. امیدوارم توضیحات ما را دوست داشته باشید.
نتیجه گیری - Python Computer Vision
از این رو ، در این آموزش کامپیوتر Python Computer Vision ، ما در مورد معنی Computer Vision در پایتون AI بحث کردیم. همچنین ، ما طراحی با OpenCV ، Detecting Edges و Faces را دیدیم. علاوه بر این ، ما تشخیص چشم را در پایتون Computer Vision آموختیم. آیا این توضیحات برای شما مفید است؟ نظرات خود را در نظرات بیان کنید.