ادغام با هوش مصنوعی: چگونه مغز بسازیم -رابط رایانه ای برای ارتباط با Google با استفاده از Keras و OpenBCI
ادغام با هوش مصنوعی: چگونه مغز بسازیم -رابط رایانه ای برای ارتباط با Google با استفاده از Keras و OpenBCI
ایلان ماسک و Neuralink می خواهند یک رابط مغز و رایانه بسازند که بتواند به عنوان لایه سوم مغز عمل کند و به انسان این امکان را بدهد که با Artificial ارتباط همزیستی برقرار کند. هوش.
اما اگر می توانید این کار را انجام دهید؟
در یک شکل (بسیار) محدود ، در واقع می توانید.
سابقه
< p> رابط مغز و رایانه (BCI) به طور گسترده به هر سیستمی اطلاق می شود که ارتباط مستقیمی بین سیستم عصبی و یک دستگاه الکترونیکی برقرار کند. این دستگاه ها ممکن است با جراحی در مغز کاشته شوند یا خارجی باشند. پارادایم های معمولی شامل اجازه دادن به کاربر برای کنترل یک محرک یا صفحه کلید ، اجازه دادن به یک دستگاه برای ارسال داده های حسی به کاربر ، یا ارتباط دو طرفه شامل داده های حسی و کنترل حرکتی (یعنی بازوی مصنوعی که ورودی کنترل موتور را دریافت می کند و داده های حسی را برای فشار ارسال می کند) یا درجه حرارت)از نظر تاریخی ، پروتزهای عصبی انگیزه اصلی تحقیقات BCI بوده است. این شامل اندام مصنوعی برای افراد قطع عضو ، کاشت حلزون شنوایی برای ناشنوایان و تحریک عمیق مغزی برای افرادی است که از تشنج رنج می برند. در حال حاضر ، این دستگاه ها زندگی میلیون ها نفر را بهبود بخشیده است و استفاده گسترده از آنها مزایای دستیابی به ارتباط مستقیم دو طرفه بین مغز و دستگاه های الکترونیکی را نشان می دهد. با این حال ، کاربردهای احتمالی این فناوری بسیار فراتر از مراقبت های بهداشتی است. حتی در حوزه پروتزهای عصبی ، ما می توانیم فراتر از ترمیم تصور کنیم و به افزایش توانایی های خود فراتر از سطوح طبیعی انسان فکر کنیم. اعضای مصنوعی ممکن است روزی به حدی پیشرفت کنند که با هر معیار عینی از همتایان طبیعی خود برتر باشند. این اندام ها ممکن است شبیه اندام های معمولی به نظر برسند ، اما بسیار قوی تر و چابک تر هستند. مثال دیگر می تواند چشم مصنوعی باشد که وضوح بسیار بیشتری نسبت به چشم انسان دارد ، توانایی بزرگنمایی یا کوچک نمایی و مشاهده در طیف UV یا IR را دارد.
با توجه به شناخت ، امکانات حتی جالب تر می شوند. و شکل گیری مهارت یک مطالعه اخیر نشان می دهد که تحریک قسمت های خاصی از مغز باعث بهبود حافظه و به یاد آوردن آن می شود. آزمایش های دیگر موفق شده اند به طور مصنوعی خاطرات را در حیوانات کاشته باشند. به عنوان مثال ، ممکن است بتوان از روشهای این مطالعات برای افزایش توانایی یادگیری سریع یک ابزار استفاده کرد. یا شاید بتوان محرک های عصبی و حسگرهای مختلف را برای ایجاد "واحد پردازش حسابی" ترکیب کرد که بتواند تشخیص دهد که مناطق خاصی از مغز مرتبط با استدلال ریاضی یا منطقی فعال شده و با آنها ارتباط برقرار می کند.
این گسترش این تقویت شناختی است که ایلان ماسک و Neuralink می خواهند دنبال کنند. به گفته ماسک و بسیاری از نظریه پردازان برجسته هوش مصنوعی ، یک مانع کلیدی در پیشرفت فکری بشری نسبت به هوش مصنوعی ، مشکل پهنای باند است: اگرچه رایانه ها و هوش مصنوعی در حال پردازش و تولید دانش سریعتر و بیشتر هستند ، اما ما با محدودیت های فوری و اساسی در توانایی خود روبرو هستیم. برای انجام همین کار ما اطلاعات را در درجه اول از طریق حواس و توانایی تفسیر زبان به دست می آوریم. در زمانی که خواندن و فهمیدن آن به چشم ها و قشر بینایی شما نیاز داردیک جمله واحد ، رایانه می تواند هزاران صفحه متن را اسکن کند. می توان تصور کرد که در چند دهه آینده ، ما ممکن است هوش مصنوعی پیشرفته ای داشته باشیم که روی سخت افزارهای تخصصی نورومورفیک کار می کند ، با مدل های فوق العاده دقیق نحوه کار جهان و توانایی تجزیه و تحلیل و درک میلیون ها سند در عرض چند دقیقه ، تصمیم گیری و استنباط هایی که بسیار فراتر از انسان است. درک مطلب. در جهانی که به طور فزاینده ای به تصمیم گیری های مبتنی بر هوش مصنوعی وابسته است ، ممکن است انسانها در تمام بخشهای تصمیم گیری تجاری ، علمی و سیاسی منسوخ شوند. مغز ما برای بازی شطرنج با تریلیون ها مهره یا درک استراتژی های محاسبه شده که میلیون ها حرکت پیش رو را برنامه ریزی می کند ، تکامل نیافته است. این ترس از این جعبه سیاه فوق العاده است که انگیزه بسیاری از کارهای فعلی در Neuralink ، Kernel و چندین سازمان مرتبط دیگر را ایجاد می کند.
بیشتر تحقیقات پیشرو در فناوری BCI به دنبال به حداکثر رساندن اطلاعات هستند پهنای باند ، معمولاً از طریق روشهای تهاجمی که الکترودها را مستقیماً در مغز یا اعصاب کاشته می شود. با این حال ، روشهای غیر تهاجمی ، به ویژه الکتروانسفالوگرافی (EEG) و الکترومیوگرافی (EMG) به طور معمول با موفقیت قابل توجهی استفاده می شود. اینها شامل قرار دادن الکترودهایی روی سطح سر (EEG) یا پوست بالای عضلات (EMG) برای اندازه گیری فعالیت الکتریکی تجمع یافته در زیر است. جزئیات این داده ها پایین است و فاصله زیادی با سطح دقت و پهنای باند دارد که در نهایت برای تحقق اهداف بلندپروازانه تحقیقات BCI مورد نیاز است. با این وجود ، BCI های دارای EEG/EMG به موفقیت های باورنکردنی مانند کنترل هواپیماهای بدون سرنشین ، بازی های ویدئویی و صفحه کلیدها با فکر دست یافته اند ، و آنها نگاه کوچکی به امکاناتی که تحقیقات بیشتر ممکن است باز کند ، ارائه می دهند. علاوه بر این ، چندین شرکت مانند Cognixion و Neurable در حال بررسی برنامه های کاربردی BCI های مبتنی بر EEG هستند و با پروژه های هیجان انگیز زیادی که در دست انجام است ، بودجه و پشتیبانی قابل توجهی دریافت کرده اند.
مرور کلی
در این پروژه ، ما یک ارتباط مستقیم بین سیستم عصبی خود و یک عامل هوش مصنوعی خارجی ایجاد کنید. این نماینده ممکن است هر چیزی باشد که بتوانید برای آن یک API دریافت کنید: Google Assistant ، Siri ، Alexa ، Watson ، و غیره. خدمات مانند دیکشنری یا YouTube نیز واجد شرایط هستند ، اما اینها برنامه ها را به درخواستهای محتوا محدود می کند تا درخواستهای عمومی.
برای اهداف این پروژه ، ما مستقیماً از جستجوی Google پرس و جو می کنیم زیرا بیشترین انعطاف پذیری را دارد و راحت ترین راه برای تنظیم است. پس از اتمام ، شما باید بتوانید تعداد کمی از اصطلاحات را در Google به سادگی در مورد آنها جستجو کنید.
تکنیکی که ما استفاده می کنیم از سیگنال های عصبی ایجاد شده توسط مغز شما در فرایند فراخطی استفاده می کند. این "مونولوگ داخلی" است که هنگامی که به آرامی و عمداً می خوانید یا فکر می کنید در داخل سر شما اتفاق می افتد. ممکن است متوجه شده باشید که هنگام سکوت خواندن این کار را انجام می دهید ، گاهی اوقات تا جایی که فک و زبان خود را با ظرافت حرکت می دهید بدون اینکه حتی متوجه شوید. همچنین ممکن است هنگام دریافت نکات مربوط به SAT ، MCAT ، GRE یا سایر آمادگی های استاندارد استاندارد با این مفهوم برخورد کرده باشید. به داوطلبان آزمون توصیه می شود از فراخوانی خودداری کنند زیرا این یک عادت بد است که سرعت خواندن را کند می کند.زیرا مغز سیگنال هایی را به حنجره شما ارسال می کند که مربوط به کلماتی است که شما فکر می کنید ، حتی اگر قصد ندارید آنها را با صدای بلند بیان کنید. با قرار دادن الکترودهایی روی صورت بر روی اعصاب حنجره و فک پایین ، می توانیم سیگنال های مربوط به کلمات خاص را ضبط کرده و از آنها برای آموزش مدلهای یادگیری عمیق که بین کلمات مختلف تشخیص می دهند استفاده کنیم. به عبارت دیگر (بدون استفاده از کلمات کلیدی) ، ما می توانیم تشخیص دهیم که شما در مورد یک کلمه خاص به سادگی از عملکرد آن فکر می کنید.
 مغز و اعصاب حنجره
مغز و اعصاب حنجره این فناوری محدودیت هایی دارد و به هیچ وجه مناسب یا آماده استفاده عملی نیست. با این حال ، از اولین تظاهرات خود در دنیای واقعی دو سال پیش توسط MIT Media Lab ، با موفقیت در دستگاه هایی استفاده می شود که به کاربران امکان می دهد در هنگام بازی شطرنج ریاضیات ، تماس های تلفنی ، سفارش پیتزا و حتی دریافت کمک را انجام دهند.
 هدست آزمایشگاهی MIT Media AlterEgo
هدست آزمایشگاهی MIT Media AlterEgo SETUP & MATERIALS
< p> ابزار سخت افزاری اولیه مورد نیاز یک برد OpenBCI Ganglion است. گزینه های سخت افزاری دیگری نیز وجود دارد ، اما من OpenBCI را به عنوان یکی از بزرگترین انجمن های توسعه دهندگان برای پشتیبانی یافتم. قیمت شما حدود 200 دلار است ، اما با توجه به چیزهای باورنکردنی که می توانید با آن بسازید ، ارزشش را دارد. برد و الکترود OpenBCI
برد و الکترود OpenBCI علاوه بر برد ، به الکترودها و سیم ها نیز نیاز دارید. مجموعه ای از الکترودهای فنجان طلا و ژل الکترود باید 50 دلار هزینه داشته باشد و خوب کار کند. متناوبا ، می توانید یک کیت استارت OpenBCI کامل ، که شامل برد و چند نوع الکترود خشک و همچنین یک هدبند الکترود است ، به قیمت 465 دلار تهیه کنید. این کمی گران است ، بنابراین تنظیم جام طلا کاملاً خوب است. با این حال ، اگر قصد دارید با سایر کاربردهای BCI ، مانند VR (آموزش استفاده از Unity VR به زودی!) آزمایش کنید ، هدبند و الکترودهای خشک تجربه بسیار بهتری را ایجاد می کنند.
Biosensing Starter Kit
OpenBCI همچنین تخته 8 و 16 کانال را ارائه می دهد. اینها کیفیت داده بالاتری را ارائه می دهند ، اما 4 کانال Ganglion برای این پروژه مناسب است. ترمینال خود را باز کنید و دستور زیر را تایپ کنید:
python3 --version
اگر پایتون ندارید یا نسخه قدیمی تری دارید ، وارد کنید: pre> $ sudo apt-get update $ sudo apt-get install python3.6
اکنون ، فهرست pyOpenBCI را بارگیری یا کلون کنید.
فهرست را به مخزن تغییر دهید و دستور زیر را برای نصب بسته های پیش نیاز اجرا کنید: < /p>
$ pip install numpy pyserial bitstring xmltodict request bluepy
اکنون آماده نصب pyOpenBCI
$ pip install pyOpenBCI
برای مشاهده هستید برخی از اقدامات ، تغییر دایرکتوری به pyOpenBCI/Examples و یافتن print_raw_example.py. این فایل را با ویرایشگر کد مورد علاقه خود باز کنید و تغییرات زیر را در خط 7 ایجاد کنید:
board = OpenBCICyton (daisy = False)
باید به:
<تغییر کرد pre> board = OpenBCIGanglion (mac = '*')این به pyOpenBCI اجازه می دهد تا ماژول های مناسبی را برای برد خاصی که ما استفاده می کنیم بکار گیرد.
اکنون ، برد خود را روشن کنید. < /p>
در رایانه خود ، از فهرست Examples در ترمینال ، دستور زیر را تایپ کنید:
$ sudo python print_raw_example
بوم !! اکنون ترمینال شما باید با جریان داده های ورودی خام از روی صفحه پر شود.
ثبت سیگنال
اکنون که می توانیم سیگنال های خام را بدست آوریم ، می توانیم شروع کنیمطراحی و ساخت خط لوله داده برای شروع ، ابتدا باید داده های خام را به جریان LSL تبدیل کنیم. LSL به لایه Streaming Stream اشاره دارد و یک پروتکل است که در مرکز Swartz برای علوم اعصاب محاسباتی در UC San Diego توسعه یافته است تا ضبط و تجزیه و تحلیل جریان داده های زنده را تسهیل کند. LSL داده های EEG ما را بر روی میزبان محلی پخش می کند ، جایی که می توان آن را توسط برنامه های دیگر یا اسکریپت ها دریافت کرد.
تغییر فایل lsl_example.py در pyOpenBCI/Examples برای حذف جریان AUX ، که ما این کار را انجام می دهیم. نیازی نیست ، یک جریان نشانگر اضافه کنید:
ما اکنون باید یک مجموعه آزمایشی تعریف کنیم که داده ها را در فرم مورد نظر ما ضبط کرده و برای استفاده بیشتر ذخیره کند. ما می خواهیم آزمایش مجموعه ای از داده های سری EEG سری زمانی را که در فواصل جدا شده تولید می شود ، ایجاد کند که هر فاصله مربوط به زیر صداگذاری یک کلمه است. برای دستیابی به این هدف ، می توانیم آزمایشی را اجرا کنیم که یک جلسه ضبط با فواصل N را شروع می کند و هر فاصله T ثانیه طول می کشد. همه نمونه ها در یک بازه زمانی مشخص شده با شاخص فاصله و کلمه خاصی که به کاربر دستور داده می شود تا زیر صدا را بیان کند ، ذکر می شود.
فایل lsl-record.py از neurotech-berkeley به عنوان یک نقطه شروع خوب عمل می کند. مطابق با تنظیمات تعریف شده ما فایل را اصلاح کنید:
شما می توانید اصطلاح BankBank (خط 64) را برای آزمایش ترکیب های مختلف کلمات در زمینه های مختلف تنظیم کنید. همچنین می توانید مدت زمان پیش فرض (خط 12) را قبل از هر جلسه تنظیم کنید.
اکنون زمان قسمت سرگرم کننده است! الکترودها را به برد خود وصل کنید:
 4 کانال چپ EEG ، راست 2 است کانال ها به حالت اولیه هستند
4 کانال چپ EEG ، راست 2 است کانال ها به حالت اولیه هستند آنها را با تنظیمات زیر روی صورت خود بچسبانید:

یک مکان آرام برای نشستن پیدا کنید و خطوط زیر را در پایانه های جداگانه وارد کنید:
//ترمینال 1: داده های خام را به LSL تبدیل کرده و آنها را پخش می کند $ sudo python lsl_example
//ترمینال 2: جریان داده LSL را می خواند و آزمایش را اجرا می کند $ sudo python lsl_record
توجه: ما به عنوان sudo اجرا می کنیم تا اسکریپت بتواند آدرس MAC صفحه را تشخیص دهد
این باید یک جلسه ضبط با مدت زمان مشخص را آغاز کند. با یک کلمه تصادفی از بانک اصطلاح از شما خواسته می شود تا در فاصله های 2 ثانیه ای صدای ضعیفی را بیان کنید. جلسات ضبط ممکن است ناراحت کننده و خواب آور باشد ، بنابراین بهتر است چندین جلسه کوچک با وقفه بین آنها انجام دهید. علاوه بر این ، در صورت بروز اختلالات مکرر (به عنوان مثال حرکات ناگهانی یا کم صدا کردن کلمه نادرست) ، تنظیم تجربی ما ممکن است منجر به کیفیت داده های ضعیف شود.
شما می توانید یک تنظیم انعطاف پذیرتر با گزینه ای برای ضربه زدن به کلید طراحی و اجرا کنید. فواصل فعلی و قبلی را با مشاهده مزاحمت حذف می کند. راه حل دیگر این است که چندین جلسه کوچک انجام دهید و داده ها را در پایان ترکیب کنید ، جلسات را با اختلالات بیش از حد کنار بگذارید. برخی از سر و صدا اجتناب ناپذیر است ، و نیازی نیست که زیاد انتخابی باشید زیرا مدل با افزایش تعداد نمونه ها انعطاف پذیرتر می شود.
برای نتایج مطلوب ، باید حداقل 1000 نمونه با کیفیت بالا برای هر کلمه در بانک کلمات شما. مناسب است تا داشته باشدقالب زیر: شاخص ها از 1 تا NumIntervals ، که مجموع SessionDuration/2 بر تعداد کل جلسات است
فایل های CSV خود را با استفاده از numpy به پایتون وارد کنید. شما باید تمام داده های خود را در Numray خط 6 x ndarray در اسکریپت خود بارگذاری کنید.
اولین قدم فیلتر کردن داده ها برای حذف نویز خارج از فرکانس های مورد علاقه ما است. به نوارهای زیر: برای فرکانسهای بین 4 هرتز تا 100 هرتز ممکن است منطقی به نظر برسد ، اما با شکست مواجه می شود زیرا 60 هرتز فرکانس شبکه برق است (ممکن است بر اساس کشور متفاوت باشد) ، که احتمالاً منبع قابل توجهی از نویز است. برای نتایج مطلوب ، باید بین 4 هرتز تا 50 هرتز فیلتر کنیم.
ما می توانیم از فیلتر Scipy's Butterworth برای انتخاب محدوده فرکانسی که می خواهیم حفظ کنیم استفاده کنیم. یک فیلتر با کد زیر تعریف کنید:
سپس ، یک ستون زمانبندی ایجاد کنید (همانطور که ما مجموعه داده های متعددی را ترکیب کرده و نشانهای زمانی اصلی را نامعتبر کرده ایم) و فیلتر را در هر کانال اعمال کنید:
پس از فیلتر شدن ، از کد زیر برای بازسازی داده های خود در یک آرایه سه بعدی ndarrray با ابعاد IntervalLength x ChannelCount x IntervalCount استفاده کنید.
آنچه ما با کد فوق به طور م doneثر انجام داده ایم ، تبدیل داده های سری زمانی به داده های تصویر است به ممکن است کمی عجیب به نظر برسد ، اما می توانید هر 2 ثانیه را به عنوان یک تصویر در نظر بگیرید ، هر پیکسل مربوط به مقدار سیگنال به دست آمده در مختصات خاص (channelNumber ، lineNumber) است. به عبارت دیگر ، ما مجموعه ای از تصاویر IntervalCount داریم که اندازه هر یک از آنها IntervalLength x CannelCount است.
 اولین 120 نقطه داده در فاصله EEG
اولین 120 نقطه داده در فاصله EEG این تکنیک ، که توسط جاستین الوی در پروژه ای مشابه نشان داده شد ، فوق العاده قدرتمند است زیرا به ما اجازه می دهد داده های سری زمانی را طوری درمان کنیم که گویی داده های تصویری بودند که به ما اجازه می داد از قدرت بینایی رایانه و شبکه های عصبی کانولوشنال (CNN) استفاده کنیم. شما حتی می توانید یک فرعی خاص را با ترسیم آن به صورت تصویر تجسم کنید. تعیین فرکانس هایی که باید به دنبال آن باشد.
اکنون ما آماده شروع ساخت CNN هستیم. از آنجا که ما فقط 1 بعد رنگ داریم ، می توانیم از یک CNN 1 بعدی با ابعاد ورودی IntervalLength و ChannelCount استفاده کنیم. ممکن است با پارامترها و معماری های مختلف آزمایش کنید. من بر روی یک لایه متحرک تک ، دو لایه کاملاً متصل و دو لایه جمع کننده مستقر شدم.
برای تجزیه و تحلیل دقیق تر CNN های تک بعدی و نحوه کاربرد آنها در داده های سری زمانی ، به این مقاله توسط نیلس مراجعه کنید. آکرمن.
ما در حال حاضر مدلی داریم که باید بتواند فاصله ای از داده های EEG را با یک کلمه خاص در بانک کلمات شما مطابقت دهد.
بیایید ببینیم که چقدر خوب عمل می کند. مدل را روی داده های آزمایش اعمال کنید و نتایج پیش بینی شده را با نتایج واقعی مقایسه کنید.
# مدل آزمایش y_preditted = model.predict (X_test)
بادو کلمه در عبارت بانک ، من توانستم به 90 درصد دقت دست پیدا کنم. همانطور که انتظار می رفت ، دقت با کلمات اضافی کمی کاهش یافت ، با 86٪ برای سه راه و 81٪ برای چهار جهت.
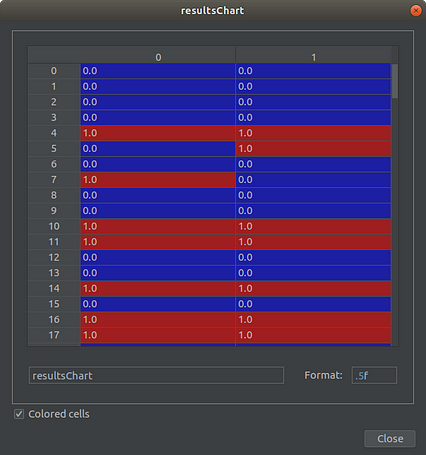 نمونه نمودار حقیقت از طبقه بندی دو کلمه ای. چپ واقعی است ، راست پیش بینی شده است > pp یک راه ممکن برای افزایش اندازه اصطلاح بانک بدون به خطر انداختن دقت ، ایجاد یک "اصطلاح درخت" سلسله مراتبی با پرس و جوهای چند کلمه ای است. سپس می توانید ابتدا جستجوی عمقی را روی درخت انجام دهید - هر لایه کلمات فقط با لایه های مشابه در زیر درخت مشابه با دیگران مقایسه می شود - تا بهترین مطابقت را پیدا کنید.
نمونه نمودار حقیقت از طبقه بندی دو کلمه ای. چپ واقعی است ، راست پیش بینی شده است > pp یک راه ممکن برای افزایش اندازه اصطلاح بانک بدون به خطر انداختن دقت ، ایجاد یک "اصطلاح درخت" سلسله مراتبی با پرس و جوهای چند کلمه ای است. سپس می توانید ابتدا جستجوی عمقی را روی درخت انجام دهید - هر لایه کلمات فقط با لایه های مشابه در زیر درخت مشابه با دیگران مقایسه می شود - تا بهترین مطابقت را پیدا کنید. GOOGLE SEARCH
< p> ما در حال حاضر تمام قطعات لازم برای پرس و جو از Google با استفاده از BCI شما را داریم. یک نگاشت بین فرعی و درخواستهای خاص تعریف کنید و تماس مناسب را انجام دهید:و….
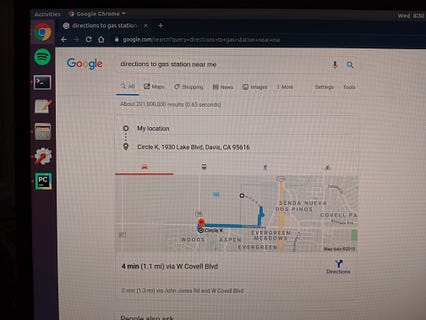
برای انجام درخواستهای زنده همانطور که فکر می کنید ، اسکریپت lsl_record.py را به عنوان یک ماژول اصلاح و وارد کنید. سپس می توانید آن را برای خواندن جریان LSL در پاسخ به ورودی کاربر برای یک فاصله 2 ثانیه ای صدا کنید.
همین! اکنون می توانید بدون گفتن یا تایپ یک کلمه در گوگل جستجو کنید.
نتیجه گیری
با یک بانک اصطلاح سه یا چهار کلمه ای نمی توانید کارهای زیادی انجام دهید (مانع اجرای اصطلاح -درختی که قبلاً ذکر شد). گذراندن همه این مراحل برای جستجوی مسیرها به نزدیکترین پمپ بنزین کمی پیچیده تر از جستجوی گوگل در حالت عادی است. با این وجود ، مهم است که در نظر بگیریم که پیشرفت های بیشتر در این فناوری به کجا می تواند منجر شود. ما می توانیم یک نسخه بهبودیافته و کمتر آشکار از این دستگاه را تصور کنیم ، نه چندان متفاوت از آنچه تیم MIT قبلاً داشته است ، که برای ناوبری ، جستجوهای وب ، پیام های متنی ، مدیریت خانه هوشمند یا هر تعداد کارهای معمول استفاده می شود. وقتی با قدرت بهبود دستیارهای هوش مصنوعی که قادر به تفسیر وابسته به زمینه هستند ، ترکیب شود ، امکانات حتی بیشتر گسترش می یابد. تحقیقات در حال انجام در شرکت ها و آزمایشگاه های دانشگاه در سراسر جهان است. ارتباطات تله پاتی ، هوش مافوق بشری ، حواس اضافی ، تجربیات شبیه سازی شده ، دیجیتالی شدن آگاهی انسان و ادغام با هوش مصنوعی همگی قابل تامل هستند. در صورت تحقق این امکانات ، آنها فقط ارتباط ما با فناوری را دوباره تعریف نمی کنند: آنها معنای انسان بودن را دوباره تعریف می کنند.
منابع
موارد زیر لیستی از منابع است و سازمانهایی که در تکمیل این پروژه و به طور کلی در یادگیری BCI مفید بودم. من می خواهم به ویژه از تیم AlterEgo در آزمایشگاه رسانه ای MIT به عنوان الهام بخش اصلی این پروژه و همچنین آقای آلوی و NeuroTech Berkeley برای کد قبلی و کمک های آموزشی آنها در جامعه BCI قدردانی کنم. علاوه بر این ، می خواهم از استادان دانشگاه کالیفرنیا ، دیویس ، به ویژه دکتر ایلیاس تاگکوپولوس ، دکتر کارن موکسون و دکتر ارکین سکر ، برای کمک و پشتیبانی مداوم تشکر کنم.

سرانجام ، من می خواهم فریاد بزرگی به صدا در آورمجوامع رو به رشد BCI/Neurotech که حمایت ، منابع و اشتیاق بی پایان برای آینده ارائه کرده اند.
اگر مایل به بحث بیشتر یا ارتباط هستید ، لطفاً با LinkedIn
تماس بگیرید.